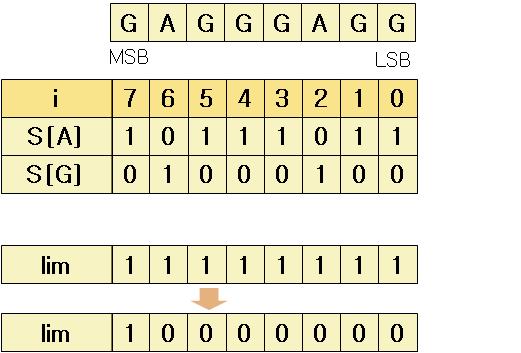
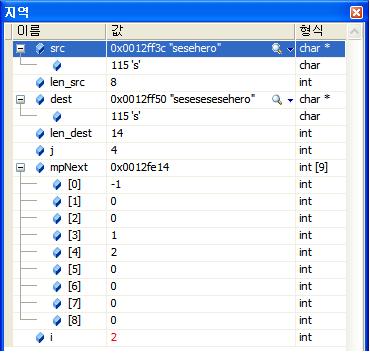
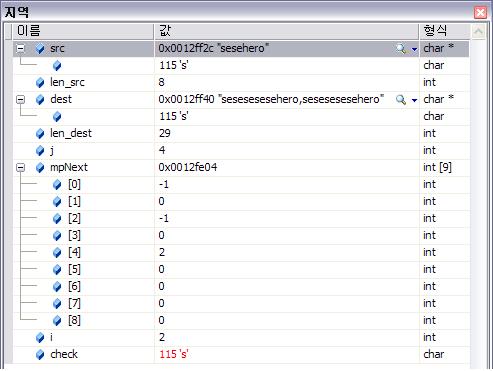
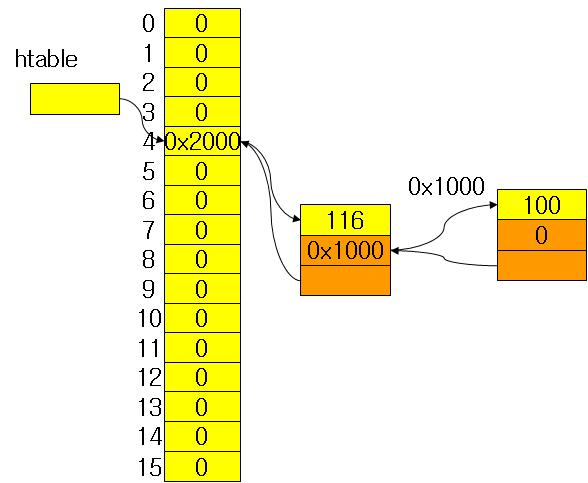
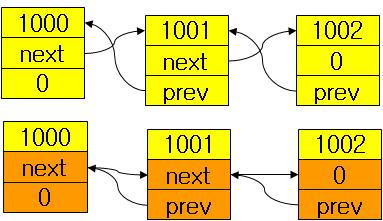
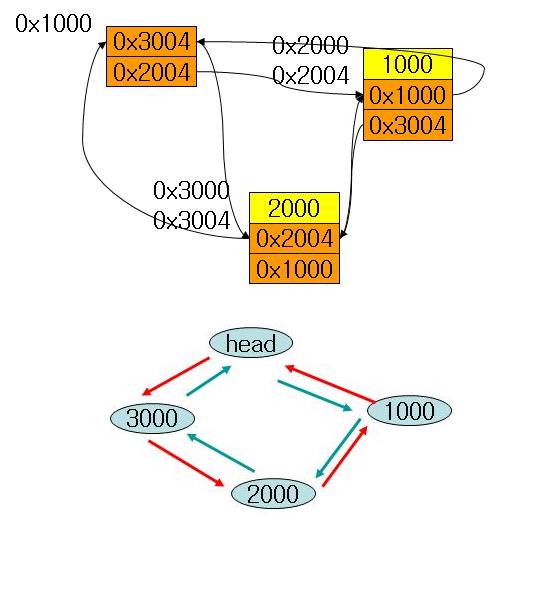
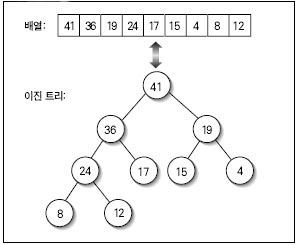
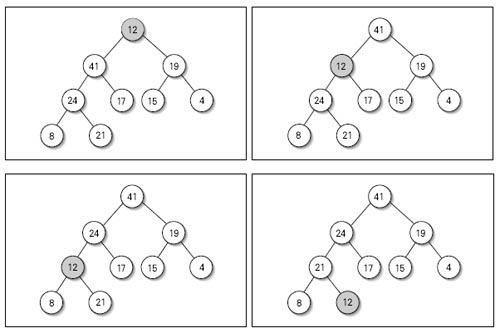
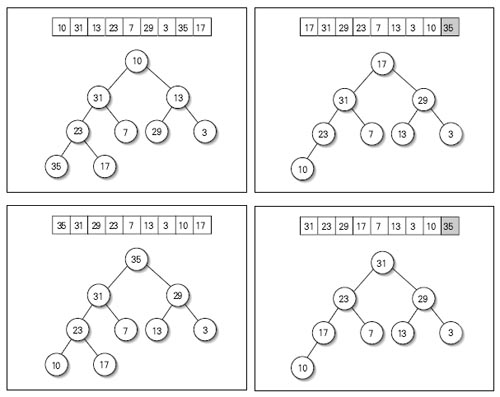
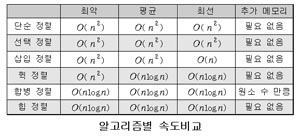
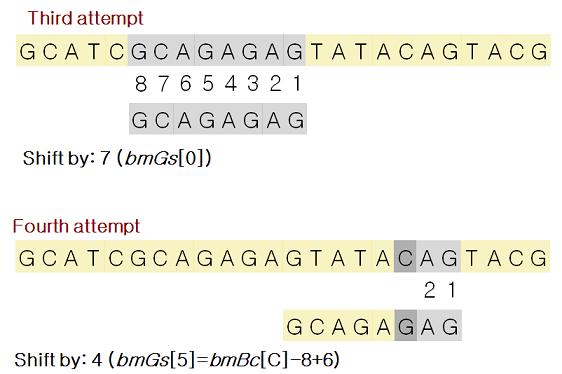Red/Black를 자바로 구현해 놓은곳 최최고~~( 자바 최신 버젼을 깔아야 한다. http://java.com )
http://www.ece.uc.edu/~franco/C321/html/RedBlack/redblack.html
http://webpages.ull.es/users/jriera/Docencia/AVL/AVL%20tree%20applet.htm
1. RedBlack.c( http://lxr.linux.no/linux-old+v2.4.20/lib/rbtree.c )
http://www.ece.uc.edu/~franco/C321/html/RedBlack/redblack.html
http://webpages.ull.es/users/jriera/Docencia/AVL/AVL%20tree%20applet.htm
1. RedBlack.c( http://lxr.linux.no/linux-old+v2.4.20/lib/rbtree.c )
more..
#include <stdio.h>
#include <stdlib.h>
typedef struct rb_node
{
struct rb_node *rb_parent;
int rb_color;
#define RB_RED 0
#define RB_BLACK 1
struct rb_node *rb_right;
struct rb_node *rb_left;
}rb_node_t;
typedef struct rb_root
{
struct rb_node *rb_node;
}rb_root_t;
typedef struct
{
int age;
struct rb_node tree;
} AGE;
#define rb_entry(ptr, type, member) \
((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
void rb_link_node(struct rb_node * node,
struct rb_node * parent,
struct rb_node ** rb_link);
AGE * rb_insert_age(struct rb_root * root,
int age,
rb_node_t * node);
void in_order( rb_node_t * p );
void __rb_rotate_left(rb_node_t * node, rb_root_t * root);
void __rb_rotate_right(rb_node_t * node, rb_root_t * root);
void rb_insert_color(rb_node_t * node, rb_root_t * root);
void display(struct rb_node *p);
void rb_erase(rb_node_t * node, rb_root_t * root);
void __rb_erase_color(rb_node_t * node, rb_node_t * parent,
rb_root_t * root);
void rb_delete( int age, struct rb_root *root);
int main()
{
struct rb_root root={0};
int i;
AGE a[10];
for(i=0; i<10; i++)
{
a[i].age = (i+1)*10;
rb_insert_age( &root, a[i].age , &a[i].tree );
display(root.rb_node);
getchar();
system("cls");
}
display(root.rb_node);
getchar();
system("cls");
rb_delete(60 , &root);
display(root.rb_node);
//in_order( root.rb_node );
return 0;
}
void rb_delete( int age, struct rb_root *root){
struct rb_node ** p = &root->rb_node;
struct rb_node * parent = NULL;
AGE *temp;
while (*p) {
parent = *p;
temp = rb_entry(parent, AGE, tree);
if ( age < temp->age )
p = &(*p)->rb_left;
else if (age > temp->age )
p = &(*p)->rb_right;
else
break;
}
if(!*p) return;
rb_erase( *p, root );
}
void display(struct rb_node *p)
{
int i;
static int x = 0;
if (p)
{
x += 2;
display(p->rb_right);
for (i = 2; i < x; i++)
printf(" ");
if( p->rb_color == 1 )
printf("[%2d]\n", rb_entry(p, AGE, tree)->age);
else
printf("<%2d>\n", rb_entry(p, AGE, tree)->age);
display(p->rb_left);
x -= 2;
}
}
void rb_link_node(struct rb_node * node,
struct rb_node * parent,
struct rb_node ** rb_link)
{
node->rb_parent = parent;
node->rb_color = RB_RED;
node->rb_left = node->rb_right = NULL;
*rb_link = node;
}
AGE * rb_insert_age(struct rb_root * root,
int age,
rb_node_t * node)
{
rb_node_t ** p = &root->rb_node;
rb_node_t * parent = NULL;
AGE *a;
while (*p)
{
parent = *p;
a = rb_entry(parent, AGE, tree);
if (age < a->age)
p = &(*p)->rb_left;
else if (age > a->age)
p = &(*p)->rb_right;
else
return 0;
}
rb_link_node(node, parent, p);
rb_insert_color(node, root);
return NULL;
}
// root -> [ 25 ]
void in_order( rb_node_t * p )
{
if(p==0) return;
in_order( p->rb_left );
printf("[%d]\n",rb_entry(p, AGE, tree)->age);
in_order( p->rb_right );
}
void __rb_rotate_left(rb_node_t * node, rb_root_t * root)
{
rb_node_t * right = node->rb_right;
if ((node->rb_right = right->rb_left))
right->rb_left->rb_parent = node;
right->rb_left = node;
if ((right->rb_parent = node->rb_parent))
{
if (node == node->rb_parent->rb_left)
node->rb_parent->rb_left = right;
else
node->rb_parent->rb_right = right;
}
else
root->rb_node = right;
node->rb_parent = right;
}
void rb_insert_color(rb_node_t * node, rb_root_t * root)
{
rb_node_t * parent, * gparent;
while ((parent = node->rb_parent) && parent->rb_color == RB_RED)
{
gparent = parent->rb_parent;
if (parent == gparent->rb_left)
{
{
register rb_node_t * uncle = gparent->rb_right;
if (uncle && uncle->rb_color == RB_RED)
{
uncle->rb_color = RB_BLACK;
parent->rb_color = RB_BLACK;
gparent->rb_color = RB_RED;
node = gparent;
continue;
}
}
if (parent->rb_right == node)
{
register rb_node_t * tmp;
__rb_rotate_left(parent, root);
tmp = parent;
parent = node;
node = tmp;
}
parent->rb_color = RB_BLACK;
gparent->rb_color = RB_RED;
__rb_rotate_right(gparent, root);
} else {
{
register rb_node_t * uncle = gparent->rb_left;
if (uncle && uncle->rb_color == RB_RED)
{
uncle->rb_color = RB_BLACK;
parent->rb_color = RB_BLACK;
gparent->rb_color = RB_RED;
node = gparent;
continue;
}
}
if (parent->rb_left == node)
{
register rb_node_t * tmp;
__rb_rotate_right(parent, root);
tmp = parent;
parent = node;
node = tmp;
}
parent->rb_color = RB_BLACK;
gparent->rb_color = RB_RED;
__rb_rotate_left(gparent, root);
}
}
root->rb_node->rb_color = RB_BLACK;
}
void __rb_rotate_right(rb_node_t * node, rb_root_t * root)
{
rb_node_t * left = node->rb_left;
if ((node->rb_left = left->rb_right))
left->rb_right->rb_parent = node;
left->rb_right = node;
if ((left->rb_parent = node->rb_parent))
{
if (node == node->rb_parent->rb_right)
node->rb_parent->rb_right = left;
else
node->rb_parent->rb_left = left;
}
else
root->rb_node = left;
node->rb_parent = left;
}
void __rb_erase_color(rb_node_t * node, rb_node_t * parent,
rb_root_t * root)
{
rb_node_t * other;
while ((!node || node->rb_color == RB_BLACK) && node != root->rb_node)
{
if (parent->rb_left == node)
{
other = parent->rb_right;
if (other->rb_color == RB_RED)
{
other->rb_color = RB_BLACK;
parent->rb_color = RB_RED;
__rb_rotate_left(parent, root);
other = parent->rb_right;
}
if ((!other->rb_left ||
other->rb_left->rb_color == RB_BLACK)
&& (!other->rb_right ||
other->rb_right->rb_color == RB_BLACK))
{
other->rb_color = RB_RED;
node = parent;
parent = node->rb_parent;
}
else
{
if (!other->rb_right ||
other->rb_right->rb_color == RB_BLACK)
{
register rb_node_t * o_left;
if ((o_left = other->rb_left))
o_left->rb_color = RB_BLACK;
other->rb_color = RB_RED;
__rb_rotate_right(other, root);
other = parent->rb_right;
}
other->rb_color = parent->rb_color;
parent->rb_color = RB_BLACK;
if (other->rb_right)
other->rb_right->rb_color = RB_BLACK;
__rb_rotate_left(parent, root);
node = root->rb_node;
break;
}
}
else
{
other = parent->rb_left;
if (other->rb_color == RB_RED)
{
other->rb_color = RB_BLACK;
parent->rb_color = RB_RED;
__rb_rotate_right(parent, root);
other = parent->rb_left;
}
if ((!other->rb_left ||
other->rb_left->rb_color == RB_BLACK)
&& (!other->rb_right ||
other->rb_right->rb_color == RB_BLACK))
{
other->rb_color = RB_RED;
node = parent;
parent = node->rb_parent;
}
else
{
if (!other->rb_left ||
other->rb_left->rb_color == RB_BLACK)
{
register rb_node_t * o_right;
if ((o_right = other->rb_right))
o_right->rb_color = RB_BLACK;
other->rb_color = RB_RED;
__rb_rotate_left(other, root);
other = parent->rb_left;
}
other->rb_color = parent->rb_color;
parent->rb_color = RB_BLACK;
if (other->rb_left)
other->rb_left->rb_color = RB_BLACK;
__rb_rotate_right(parent, root);
node = root->rb_node;
break;
}
}
}
if (node)
node->rb_color = RB_BLACK;
}
void rb_erase(rb_node_t * node, rb_root_t * root)
{
rb_node_t * child, * parent;
int color;
if (!node->rb_left)
child = node->rb_right;
else if (!node->rb_right)
child = node->rb_left;
else
{
rb_node_t * old = node, * left;
node = node->rb_right;
while ((left = node->rb_left))
node = left;
child = node->rb_right;
parent = node->rb_parent;
color = node->rb_color;
if (child)
child->rb_parent = parent;
if (parent)
{
if (parent->rb_left == node)
parent->rb_left = child;
else
parent->rb_right = child;
}
else
root->rb_node = child;
if (node->rb_parent == old)
parent = node;
node->rb_parent = old->rb_parent;
node->rb_color = old->rb_color;
node->rb_right = old->rb_right;
node->rb_left = old->rb_left;
if (old->rb_parent)
{
if (old->rb_parent->rb_left == old)
old->rb_parent->rb_left = node;
else
old->rb_parent->rb_right = node;
} else
root->rb_node = node;
old->rb_left->rb_parent = node;
if (old->rb_right)
old->rb_right->rb_parent = node;
goto color;
}
parent = node->rb_parent;
color = node->rb_color;
if (child)
child->rb_parent = parent;
if (parent)
{
if (parent->rb_left == node)
parent->rb_left = child;
else
parent->rb_right = child;
}
else
root->rb_node = child;
color:
if (color == RB_BLACK)
__rb_erase_color(child, parent, root);
}
#include <stdlib.h>
typedef struct rb_node
{
struct rb_node *rb_parent;
int rb_color;
#define RB_RED 0
#define RB_BLACK 1
struct rb_node *rb_right;
struct rb_node *rb_left;
}rb_node_t;
typedef struct rb_root
{
struct rb_node *rb_node;
}rb_root_t;
typedef struct
{
int age;
struct rb_node tree;
} AGE;
#define rb_entry(ptr, type, member) \
((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
void rb_link_node(struct rb_node * node,
struct rb_node * parent,
struct rb_node ** rb_link);
AGE * rb_insert_age(struct rb_root * root,
int age,
rb_node_t * node);
void in_order( rb_node_t * p );
void __rb_rotate_left(rb_node_t * node, rb_root_t * root);
void __rb_rotate_right(rb_node_t * node, rb_root_t * root);
void rb_insert_color(rb_node_t * node, rb_root_t * root);
void display(struct rb_node *p);
void rb_erase(rb_node_t * node, rb_root_t * root);
void __rb_erase_color(rb_node_t * node, rb_node_t * parent,
rb_root_t * root);
void rb_delete( int age, struct rb_root *root);
int main()
{
struct rb_root root={0};
int i;
AGE a[10];
for(i=0; i<10; i++)
{
a[i].age = (i+1)*10;
rb_insert_age( &root, a[i].age , &a[i].tree );
display(root.rb_node);
getchar();
system("cls");
}
display(root.rb_node);
getchar();
system("cls");
rb_delete(60 , &root);
display(root.rb_node);
//in_order( root.rb_node );
return 0;
}
void rb_delete( int age, struct rb_root *root){
struct rb_node ** p = &root->rb_node;
struct rb_node * parent = NULL;
AGE *temp;
while (*p) {
parent = *p;
temp = rb_entry(parent, AGE, tree);
if ( age < temp->age )
p = &(*p)->rb_left;
else if (age > temp->age )
p = &(*p)->rb_right;
else
break;
}
if(!*p) return;
rb_erase( *p, root );
}
void display(struct rb_node *p)
{
int i;
static int x = 0;
if (p)
{
x += 2;
display(p->rb_right);
for (i = 2; i < x; i++)
printf(" ");
if( p->rb_color == 1 )
printf("[%2d]\n", rb_entry(p, AGE, tree)->age);
else
printf("<%2d>\n", rb_entry(p, AGE, tree)->age);
display(p->rb_left);
x -= 2;
}
}
void rb_link_node(struct rb_node * node,
struct rb_node * parent,
struct rb_node ** rb_link)
{
node->rb_parent = parent;
node->rb_color = RB_RED;
node->rb_left = node->rb_right = NULL;
*rb_link = node;
}
AGE * rb_insert_age(struct rb_root * root,
int age,
rb_node_t * node)
{
rb_node_t ** p = &root->rb_node;
rb_node_t * parent = NULL;
AGE *a;
while (*p)
{
parent = *p;
a = rb_entry(parent, AGE, tree);
if (age < a->age)
p = &(*p)->rb_left;
else if (age > a->age)
p = &(*p)->rb_right;
else
return 0;
}
rb_link_node(node, parent, p);
rb_insert_color(node, root);
return NULL;
}
// root -> [ 25 ]
void in_order( rb_node_t * p )
{
if(p==0) return;
in_order( p->rb_left );
printf("[%d]\n",rb_entry(p, AGE, tree)->age);
in_order( p->rb_right );
}
void __rb_rotate_left(rb_node_t * node, rb_root_t * root)
{
rb_node_t * right = node->rb_right;
if ((node->rb_right = right->rb_left))
right->rb_left->rb_parent = node;
right->rb_left = node;
if ((right->rb_parent = node->rb_parent))
{
if (node == node->rb_parent->rb_left)
node->rb_parent->rb_left = right;
else
node->rb_parent->rb_right = right;
}
else
root->rb_node = right;
node->rb_parent = right;
}
void rb_insert_color(rb_node_t * node, rb_root_t * root)
{
rb_node_t * parent, * gparent;
while ((parent = node->rb_parent) && parent->rb_color == RB_RED)
{
gparent = parent->rb_parent;
if (parent == gparent->rb_left)
{
{
register rb_node_t * uncle = gparent->rb_right;
if (uncle && uncle->rb_color == RB_RED)
{
uncle->rb_color = RB_BLACK;
parent->rb_color = RB_BLACK;
gparent->rb_color = RB_RED;
node = gparent;
continue;
}
}
if (parent->rb_right == node)
{
register rb_node_t * tmp;
__rb_rotate_left(parent, root);
tmp = parent;
parent = node;
node = tmp;
}
parent->rb_color = RB_BLACK;
gparent->rb_color = RB_RED;
__rb_rotate_right(gparent, root);
} else {
{
register rb_node_t * uncle = gparent->rb_left;
if (uncle && uncle->rb_color == RB_RED)
{
uncle->rb_color = RB_BLACK;
parent->rb_color = RB_BLACK;
gparent->rb_color = RB_RED;
node = gparent;
continue;
}
}
if (parent->rb_left == node)
{
register rb_node_t * tmp;
__rb_rotate_right(parent, root);
tmp = parent;
parent = node;
node = tmp;
}
parent->rb_color = RB_BLACK;
gparent->rb_color = RB_RED;
__rb_rotate_left(gparent, root);
}
}
root->rb_node->rb_color = RB_BLACK;
}
void __rb_rotate_right(rb_node_t * node, rb_root_t * root)
{
rb_node_t * left = node->rb_left;
if ((node->rb_left = left->rb_right))
left->rb_right->rb_parent = node;
left->rb_right = node;
if ((left->rb_parent = node->rb_parent))
{
if (node == node->rb_parent->rb_right)
node->rb_parent->rb_right = left;
else
node->rb_parent->rb_left = left;
}
else
root->rb_node = left;
node->rb_parent = left;
}
void __rb_erase_color(rb_node_t * node, rb_node_t * parent,
rb_root_t * root)
{
rb_node_t * other;
while ((!node || node->rb_color == RB_BLACK) && node != root->rb_node)
{
if (parent->rb_left == node)
{
other = parent->rb_right;
if (other->rb_color == RB_RED)
{
other->rb_color = RB_BLACK;
parent->rb_color = RB_RED;
__rb_rotate_left(parent, root);
other = parent->rb_right;
}
if ((!other->rb_left ||
other->rb_left->rb_color == RB_BLACK)
&& (!other->rb_right ||
other->rb_right->rb_color == RB_BLACK))
{
other->rb_color = RB_RED;
node = parent;
parent = node->rb_parent;
}
else
{
if (!other->rb_right ||
other->rb_right->rb_color == RB_BLACK)
{
register rb_node_t * o_left;
if ((o_left = other->rb_left))
o_left->rb_color = RB_BLACK;
other->rb_color = RB_RED;
__rb_rotate_right(other, root);
other = parent->rb_right;
}
other->rb_color = parent->rb_color;
parent->rb_color = RB_BLACK;
if (other->rb_right)
other->rb_right->rb_color = RB_BLACK;
__rb_rotate_left(parent, root);
node = root->rb_node;
break;
}
}
else
{
other = parent->rb_left;
if (other->rb_color == RB_RED)
{
other->rb_color = RB_BLACK;
parent->rb_color = RB_RED;
__rb_rotate_right(parent, root);
other = parent->rb_left;
}
if ((!other->rb_left ||
other->rb_left->rb_color == RB_BLACK)
&& (!other->rb_right ||
other->rb_right->rb_color == RB_BLACK))
{
other->rb_color = RB_RED;
node = parent;
parent = node->rb_parent;
}
else
{
if (!other->rb_left ||
other->rb_left->rb_color == RB_BLACK)
{
register rb_node_t * o_right;
if ((o_right = other->rb_right))
o_right->rb_color = RB_BLACK;
other->rb_color = RB_RED;
__rb_rotate_left(other, root);
other = parent->rb_left;
}
other->rb_color = parent->rb_color;
parent->rb_color = RB_BLACK;
if (other->rb_left)
other->rb_left->rb_color = RB_BLACK;
__rb_rotate_right(parent, root);
node = root->rb_node;
break;
}
}
}
if (node)
node->rb_color = RB_BLACK;
}
void rb_erase(rb_node_t * node, rb_root_t * root)
{
rb_node_t * child, * parent;
int color;
if (!node->rb_left)
child = node->rb_right;
else if (!node->rb_right)
child = node->rb_left;
else
{
rb_node_t * old = node, * left;
node = node->rb_right;
while ((left = node->rb_left))
node = left;
child = node->rb_right;
parent = node->rb_parent;
color = node->rb_color;
if (child)
child->rb_parent = parent;
if (parent)
{
if (parent->rb_left == node)
parent->rb_left = child;
else
parent->rb_right = child;
}
else
root->rb_node = child;
if (node->rb_parent == old)
parent = node;
node->rb_parent = old->rb_parent;
node->rb_color = old->rb_color;
node->rb_right = old->rb_right;
node->rb_left = old->rb_left;
if (old->rb_parent)
{
if (old->rb_parent->rb_left == old)
old->rb_parent->rb_left = node;
else
old->rb_parent->rb_right = node;
} else
root->rb_node = node;
old->rb_left->rb_parent = node;
if (old->rb_right)
old->rb_right->rb_parent = node;
goto color;
}
parent = node->rb_parent;
color = node->rb_color;
if (child)
child->rb_parent = parent;
if (parent)
{
if (parent->rb_left == node)
parent->rb_left = child;
else
parent->rb_right = child;
}
else
root->rb_node = child;
color:
if (color == RB_BLACK)
__rb_erase_color(child, parent, root);
}